Speech usually seems simple. Air moves, vocal cords vibrate, sound comes out. But the act of speaking leaves behind another trace, one that never reaches the ear. Tiny muscles in the throat tense and shift. Skin stretches by fractions so small they are easy to miss. Those motions, a team of researchers found, may carry enough information to rebuild spoken words. This is true even when no sound is made at all.
That is the idea behind a new wearable system developed by researchers at POSTECH, or Pohang University of Science and Technology. Led by Professor Sung-Min Park and Dr. Sunguk Hong, the team created a neck-mounted device that reads subtle throat movements with light. Then, it uses artificial intelligence to decode those patterns and turn them back into speech in the user’s own synthesized voice.
The concept targets a stubborn problem. In loud places, clear communication breaks down fast. Factories, construction zones, battlefields, and even some clinical settings can make spoken words unreliable. Traditional silent speech interfaces have tried to solve that by measuring signals from the brain or muscles. This is often done through systems such as EEG or EMG. However, those approaches can be awkward, skin-bound, or difficult to use outside the lab.
This new version takes a different route. Instead of listening for sound, it watches the body’s mechanical traces of speech.
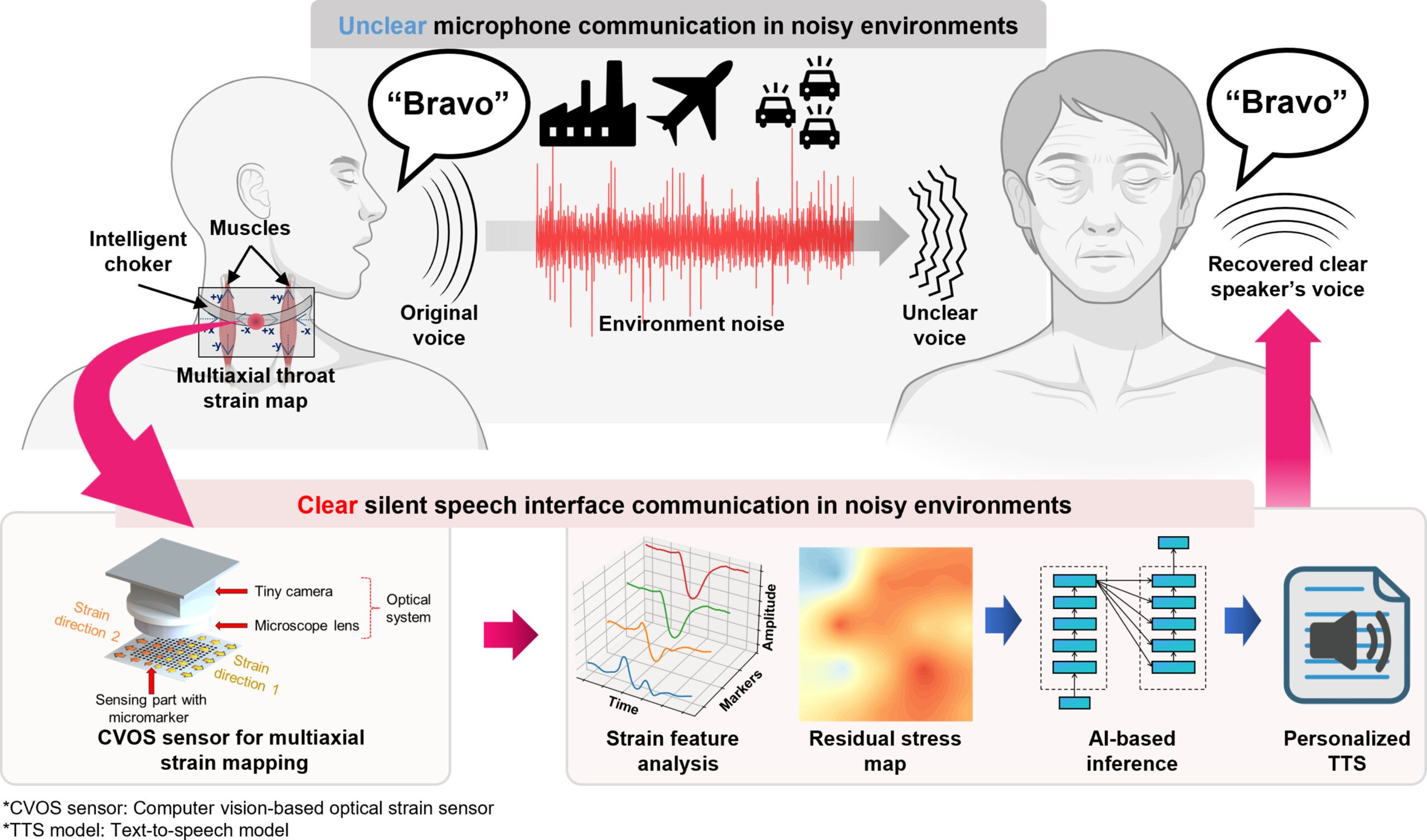
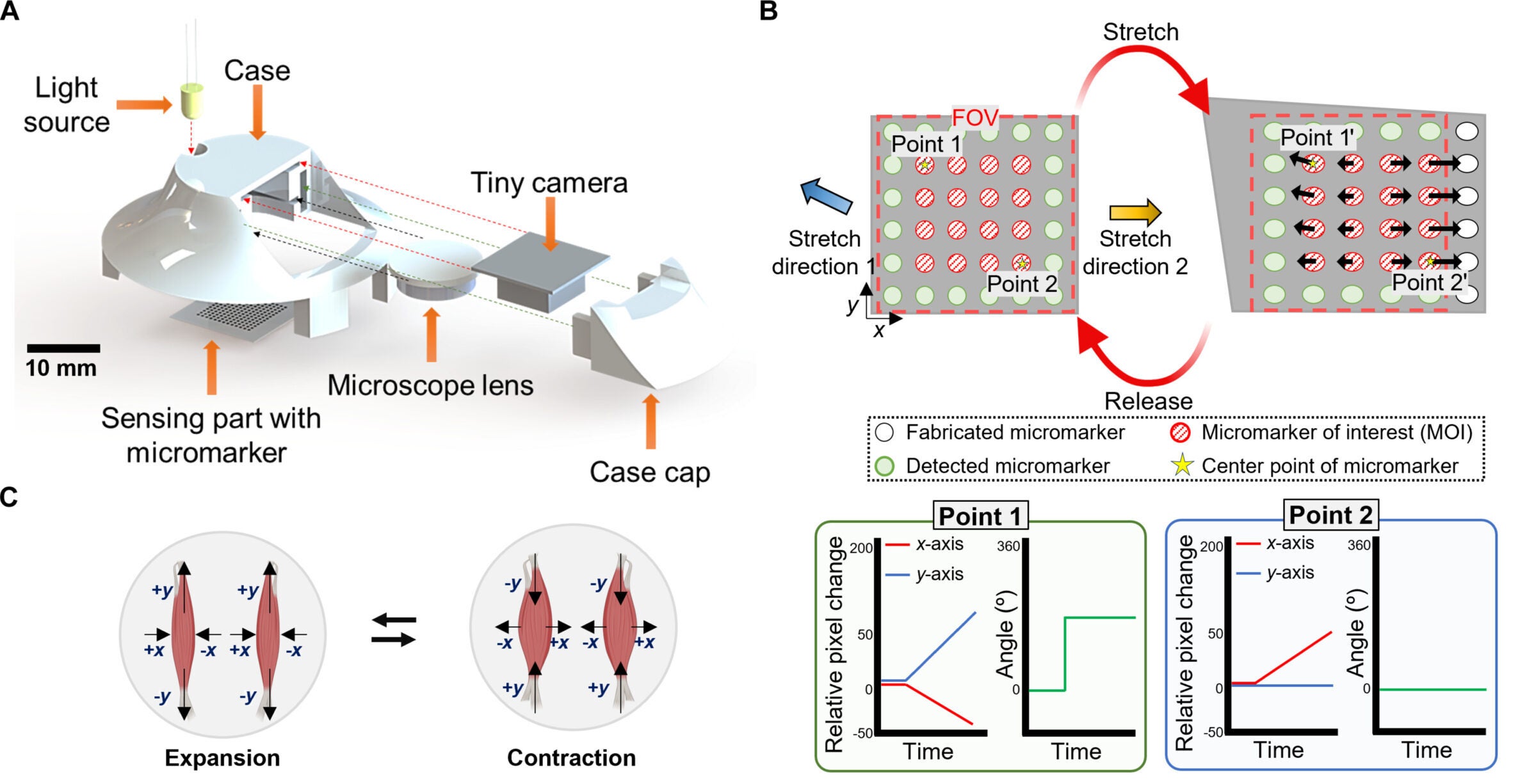
The device uses what the team calls a multiaxial strain mapping sensor. It is built around a soft silicone layer patterned with tiny black markers, paired with a miniature camera, a compact microscope lens, and an LED light. Worn as part of a choker-like neck brace, the system tracks how those markers shift. This happens when the skin and muscles around the throat move during speech.
That matters because speech is not a one-direction motion. Throat muscles expand, contract, and twist in different directions. Many earlier wearable strain sensors mainly captured one axis of motion. This limited how much detail they could gather. In contrast, this sensor instead maps both the size and direction of local strain. As a result, it produces a more complete picture of what the throat is doing.
The team reported that the sensor had a high gauge factor of 3,625, low hysteresis below 0.65 percent, and high linearity above 0.99 in its working range. It also detected strains as small as 0.02 percent. That is a level sensitive enough to pick up the fine biomechanical changes that happen during speech.
Just as important, it held up. Tests showed minimal variation between sensor samples, with a mean absolute percentage error of 2.8 percent. The device remained stable after 1,000, 5,000, and 10,000 loading cycles.
Collecting throat motion is only half the challenge. The other half is making sense of it.
The researchers built an AI pipeline that combines a convolutional neural network with a transformer model. The CNN handles fine local features in the strain maps, while the transformer helps track broader patterns over time. That hybrid setup was designed to better capture the shifting, time-dependent nature of silent speech.
The team also had to deal with a practical problem: every time a wearable device is put back on, it sits a little differently. Tightness changes. Placement shifts. Skin contact varies. Those differences can alter the signal even when the same word is spoken.
To handle that, the system measures what the researchers describe as an initial residual stress map. In plain terms, it records the baseline deformation present when the device is attached before intentional speech begins. That lets the AI adjust for attachment differences and avoid treating those changes as speech itself.
The system was trained on 5,186 samples from six participants, all healthy adults ages 23 to 32, covering the 26 words of the NATO phonetic alphabet. Rather than trying to decode open-ended conversation, the researchers focused on a controlled vocabulary. This vocabulary was already designed for clear communication in noisy settings: Alpha, Bravo, Charlie, and so on.
That choice was deliberate. Similar sounding letters can be confused over radios and in loud workplaces, which is why the NATO alphabet exists in the first place. Consequently, a silent speech system built around those words could be useful sooner than one trying to reconstruct full spontaneous language.
The classifier reached 85.8 percent accuracy across the 26 NATO words. After model compression through knowledge distillation, the system’s file size dropped from 12.4 megabytes to 3.6 megabytes. Processing speed improved from 0.018 seconds to 0.003 seconds, while accuracy remained at 82 percent. The researchers also reported a signal-to-noise ratio as high as 33.75 decibels. This was notably higher than the 10.17 decibels cited for typical commercial EMG systems.
In tests with a new user, a fine-tuning method called LoRA reached 80 percent accuracy with 20 samples per class. This compared with 76 percent for conventional fine-tuning.
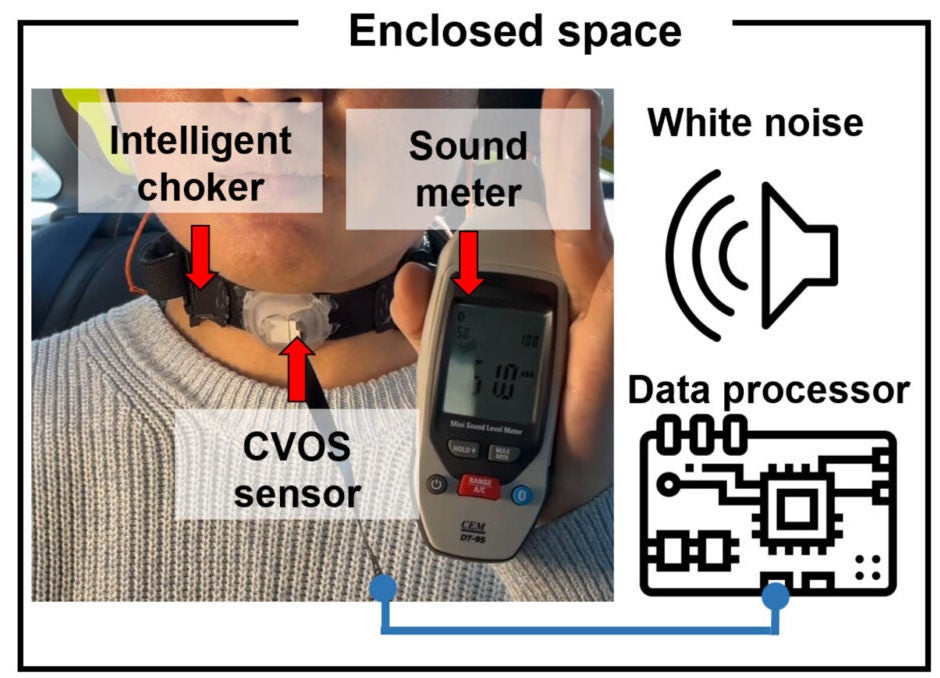
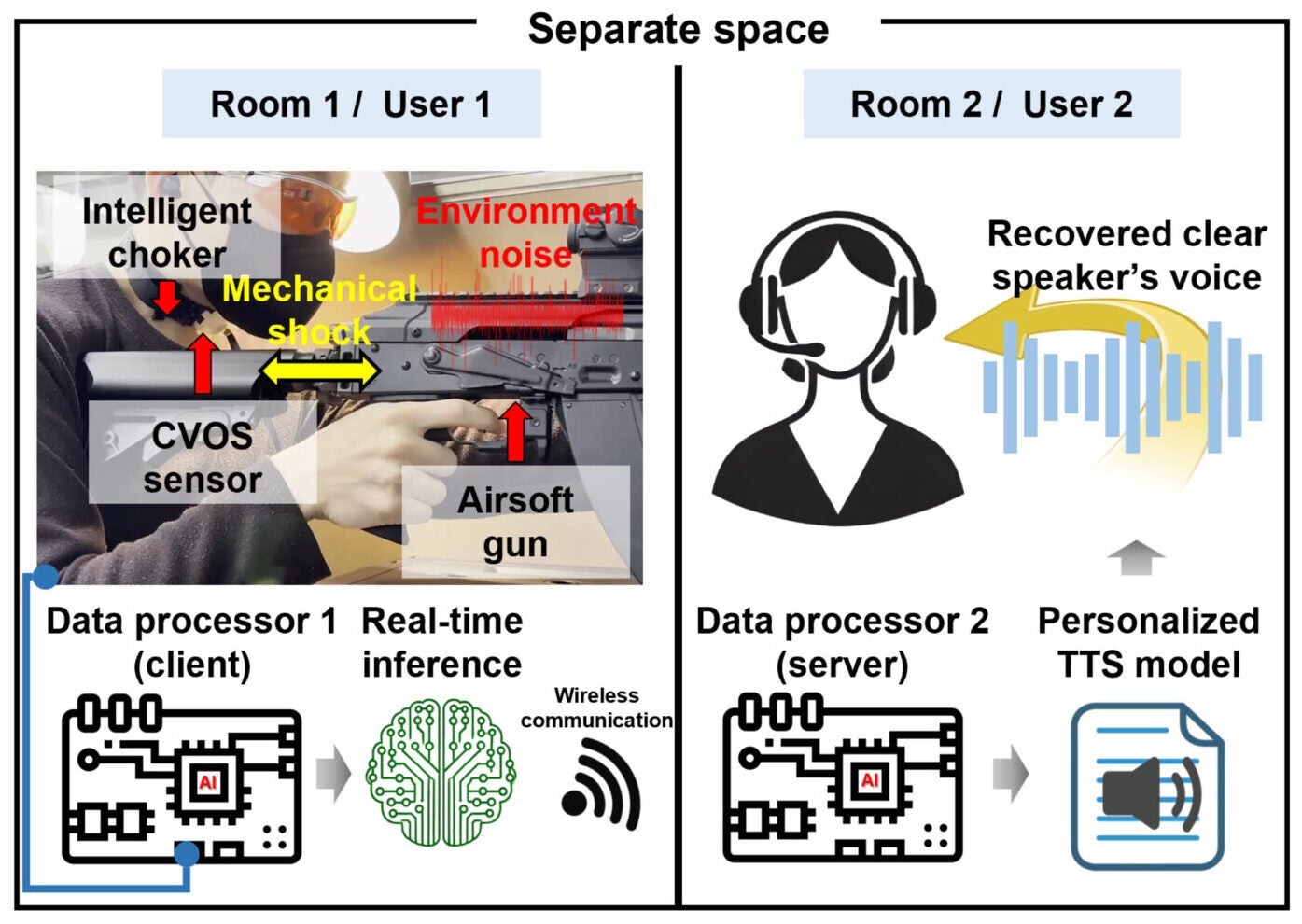
The device also stayed effective in loud settings. In experiments under 90-decibel white noise, roughly comparable to the roar of a construction site, recognition performance stayed in line with results from a normal 60-decibel environment. In another demonstration, a user wore the system while firing a gas blowback rifle in semiautomatic and full-automatic modes. The interface still distinguished intended words and transmitted them for real-time voice reconstruction.
Not every test was so clean. Performance dropped when the choker was worn too loosely or when the user spoke very loudly, likely because larger and faster muscle movements strained the limits of the current hardware. Motion was another weak point. Speaking while walking or moving the head reduced decoding accuracy. The steepest drop appeared during up-and-down head motion.
That limitation matters. A system meant for real life cannot assume people will stay still.
The researchers see several possible uses. One is clinical. People who lose their voices after vocal cord disease or laryngeal surgery may still produce throat movements tied to speech intent. Those signals could potentially be converted into an audible voice.
Another is occupational. Workers in high-noise settings may need communication tools that do not depend on microphones. There is also a quieter possibility: silent communication in places where speaking out loud is discouraged, such as libraries or conference rooms.
Professor Park said, “We hope this technology will accelerate the day when patients with speech disorders can reclaim their voices.” He added, “It is a noteworthy technology because it has a wide range of potential applications, including assisting laryngectomized patients, communicating in noisy industrial environments, and even supporting silent conversations.”
The system is not there yet. The study used a limited number of participants and a restricted vocabulary. The sampling rate was 50 hertz, which the team said fits within the biological frequency range of muscle signals. Future upgrades will need to improve speed and robustness.
The researchers also said larger datasets, more users, broader vocabularies, and better handling of motion artifacts will be necessary before the platform can become a full-scale silent speech communication tool.
This work points toward a communication system that does not depend on audible speech, handheld radios, or gel-based sensors.
If the technology improves, it could give people with speech loss a more natural way to communicate. Additionally, it could help workers exchange information in places where noise makes normal conversation unreliable.
Its biggest promise is simple: letting intended speech survive even when sound cannot.
Research findings are available online in the journal Cyborg and Bionic Systems.
The original story “New wearable uses light and AI to turn silent throat movements into audible speech” is published in The Brighter Side of News.
Like these kind of feel good stories? Get The Brighter Side of News’ newsletter.
The post New wearable uses light and AI to turn silent throat movements into audible speech appeared first on The Brighter Side of News.


