Physical AI has become one of the field’s biggest ambitions. These are machines that do more than generate text or images, and instead move through factories, roads, hospitals, and homes. The promise is easy to picture. However, the harder question is how a machine learns what people actually want it to do.
That problem sits at the center of a new paper from the Korea Advanced Institute of Science and Technology, or KAIST. The paper was accepted to ICML 2026 and chosen for an Oral presentation, a distinction given to 168 papers out of 23,918 submissions, or about 0.7 percent.
The work tackles a stubborn bottleneck in reinforcement learning, the branch of AI that trains systems to make decisions through rewards. In the real world, those rewards are hard to define. For example, a surgical robot stitching tissue, a robotic arm handling objects, or an autonomous vehicle moving through a crowded intersection may have many possible actions. Only some actions match human intentions.
For years, one of the main ways to teach that difference has been to ask people to compare short video clips and say which behavior looks better. This approach, known as preference-based reinforcement learning, can align machines with human judgment more naturally than hand-built reward rules. Yet, it also creates a practical problem of its own: people often have to label huge numbers of examples.
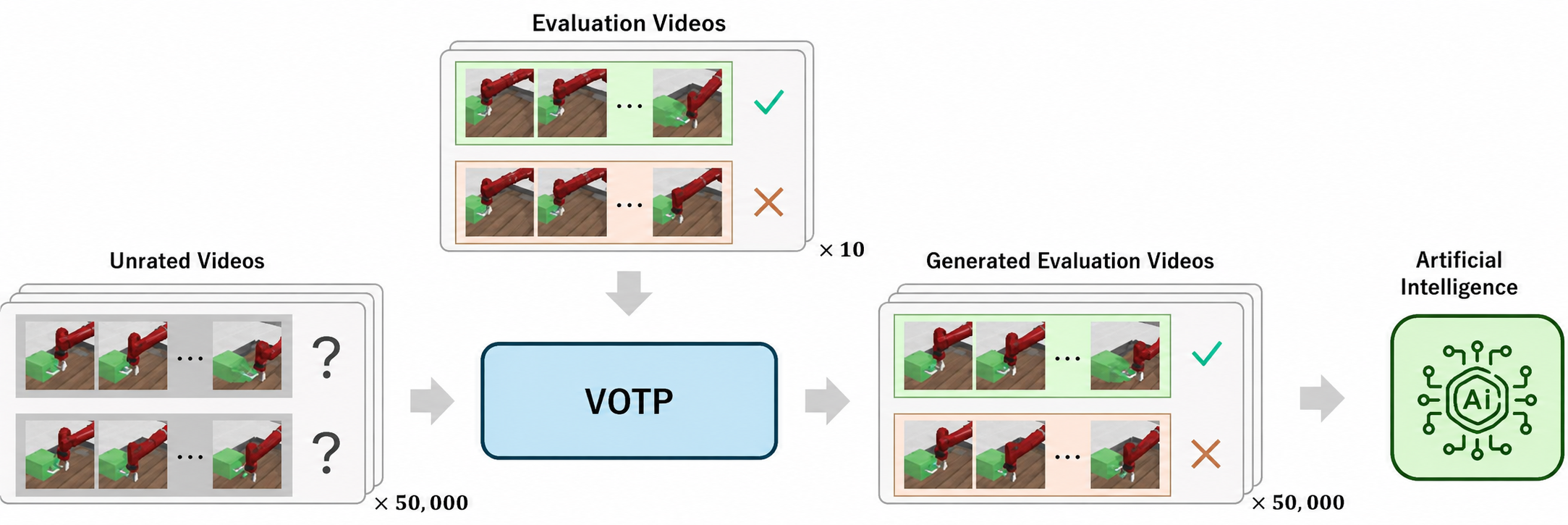
The KAIST team’s answer is a method called VOTP, short for Video-based Optimal Transport Preference labeling. Rather than depending on thousands of human judgments, it is designed to start with only a small number of labeled comparisons. In some cases, it uses as few as 10. Then it infers likely preferences for many unlabeled examples.
The idea draws on something people do all the time. A person can usually watch a few good and bad demonstrations of a task, then recognize the same pattern in a new setting. In short, VOTP tries to give machines a version of that ability.
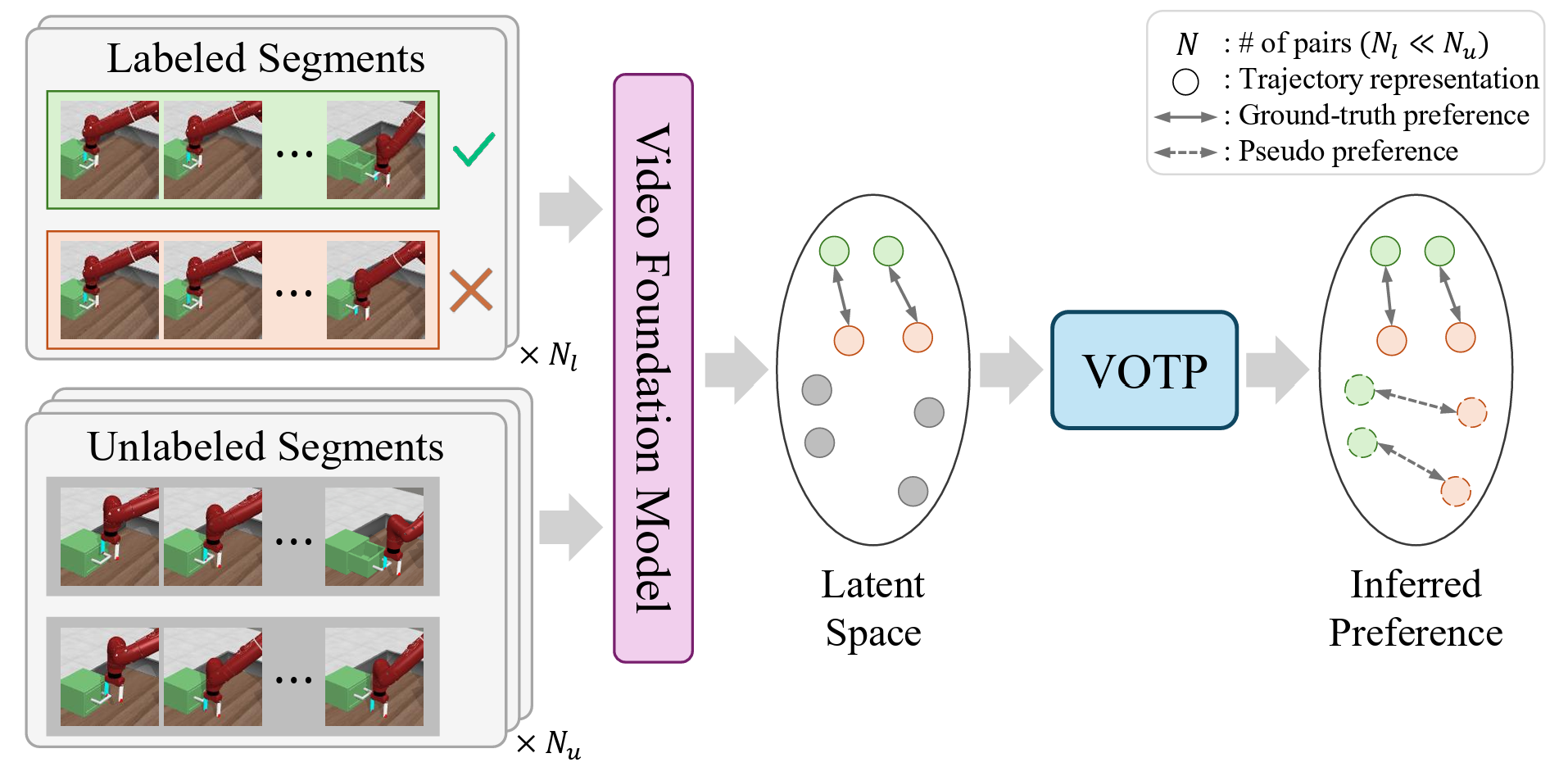
It does that by representing short trajectory segments as videos. Then it embeds them in a latent space using a pretrained video foundation model. Afterward, the system uses optimal transport, a mathematical framework for matching one distribution to another at minimum cost, to align labeled and unlabeled video segments. From those alignments, it assigns pseudo-labels to new pairs. Additionally, it uses both human-labeled and pseudo-labeled data to train a reward function.
In plain terms, the system looks at a handful of examples that people have already judged, finds visually and behaviorally similar clips in a larger pool of unlabeled data, and transfers those preferences in a structured way. The goal is not to eliminate human feedback entirely. Instead, it aims to make each piece of feedback go much further.
Professor Chang D. Yoo put it this way: “The core of physical AI is making machines understand human intentions and choose the correct actions,” and added, “Since VOTP can learn human judgment criteria with only a small number of videos, it is a core technology that will accelerate the era of robots making human-like judgments.”
The first author is PhD student Tung M. Luu from KAIST’s School of Electrical Engineering. In experiments, the team tested VOTP across simulated control tasks from D4RL locomotion benchmarks, MetaWorld manipulation tasks, and real tabletop robot tasks using a 7-degree-of-freedom Rethink Sawyer arm.
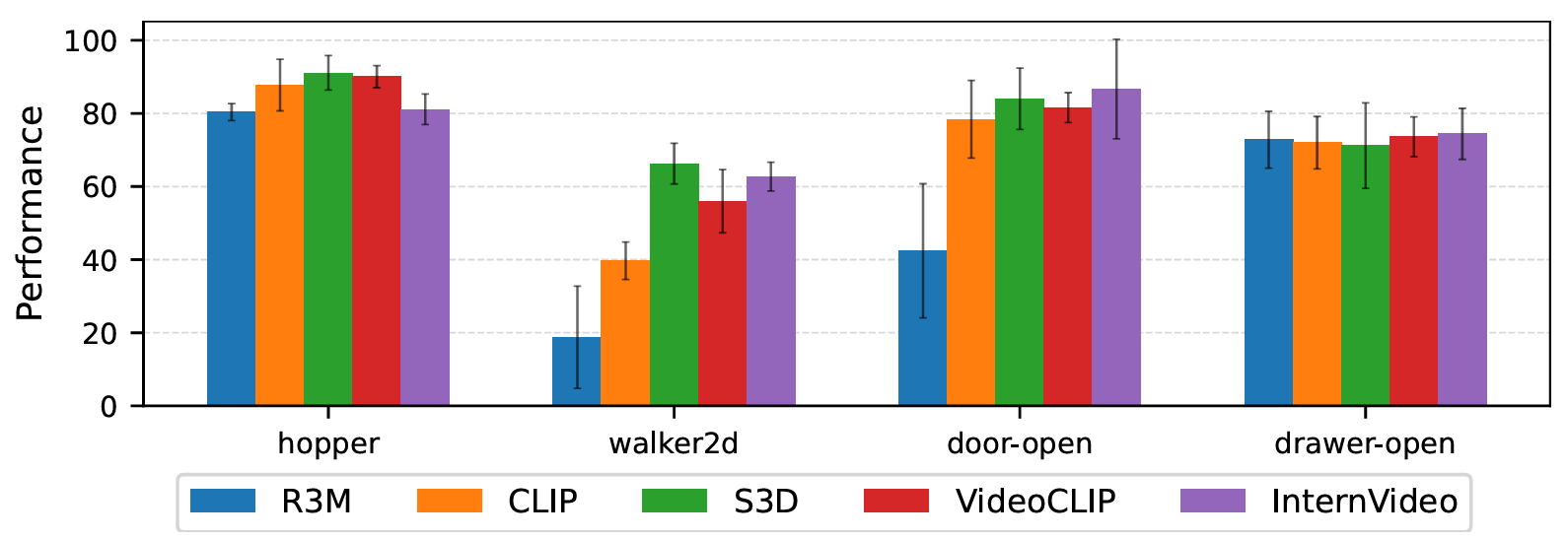
Across those settings, the paper reports that VOTP improved feedback efficiency and often outperformed standard preference-learning baselines trained with the same small label budgets. For D4RL locomotion tasks, the method closely matched the performance of an Oracle baseline that had access to synthetic preference labels for unlabeled data. In MetaWorld tasks, it posted strong gains over a baseline known as P-IQL, which learned only from the small labeled set.
One of the paper’s more striking results came in low-data conditions. In the door-open task, the authors report that VOTP with only 10 labels outperformed a policy trained with ground-truth rewards. More broadly, they found that methods relying on explicit reward models tended to be more robust when labels were scarce. Furthermore, VOTP reached strong performance with fewer labels than competing methods in most tested tasks.
The method also held up under nuisance variation. When the team changed lighting, textures, and video backgrounds in modified MetaWorld environments, VOTP maintained solid performance. That robustness matters because real machines rarely operate in perfectly clean visual settings.
The real-world robot tests may be the clearest sign of why the authors see this as foundational for physical AI. Using only 50 demonstrations collected by keyboard teleoperation, with a 50 percent success rate, the team evaluated two tasks, LiftBanana and DrawerOpen. They used just five preference labels for LiftBanana and 10 for DrawerOpen. After that, they added pseudo-labels from unlabeled pairs.
Behavior Cloning reached success rates of 20 percent on LiftBanana and 40 percent on DrawerOpen. P-IQL rose to 50 percent on both. VOTP reached 80 percent on LiftBanana and 70 percent on DrawerOpen.
The paper suggests that the extra unlabeled data helped the learned reward model separate successful behavior from failed behavior more clearly. In one analysis of reward outputs over time, the baseline P-IQL assigned high rewards to parts of a failed trajectory. However, VOTP produced a cleaner separation between success and failure.
That does not mean the problem is solved. The paper is still a research result, not a finished product dropped into hospitals or highways. Its reported gains depend on specific benchmarks, thresholds, and offline datasets. Nonetheless, the central claim is a practical one: if machines can infer more from fewer human judgments, the cost of training real-world AI systems could drop sharply.

For developers building physical AI systems, the immediate implication is cost. Preference-based training has often required hundreds or thousands of human comparisons. Therefore, a method that can stretch a handful of labeled videos into a much larger useful training signal could cut annotation burdens, shorten development cycles, and make reward learning more feasible outside well-funded labs.
That matters for robot arms, humanoid robots, industrial systems, drones, surgical robots, autonomous vehicles, and even AI agents that operate computers directly.
In each case, the challenge is similar. A machine has many possible actions. People care about whether those actions match human intent, not just whether they maximize a poorly designed score.
If VOTP continues to hold up beyond the lab, it could become one of the technical pieces that helps move physical AI from impressive demos toward systems people can trust.
Research findings are available online in the journal Open Review.
The original story “Robots that make judgments like humans are coming faster than we think” is published in The Brighter Side of News.
Like these kind of feel good stories? Get The Brighter Side of News’ newsletter.
The post Robots that make judgments like humans are coming faster than we think appeared first on The Brighter Side of News.


Leave a comment
You must be logged in to post a comment.